
Une IA hybride pour contrer le Phishing ?

Le phising : une entreprise sur 2 attaquée en 2021
D’après le Baromètre de la cybersécurité en entreprise CESIN 2022, plus d’une entreprise française sur deux a vécu au moins une cyberattaque au cours de l’année 2021 avec parfois des conséquences très graves sur l’entreprise telles que l’interruption du business, la détérioration du business ou encore la fuite des données. Tout cela engendre inévitablement un impact sur la notoriété de l’entreprise.
De plus, plus de 80 % des événements de cybersécurité impliquent des attaques de phishing. Le phishing, ou hameçonnage en français, est une cyberattaque essentiellement par courriel basée sur l’ingénierie sociale qui est une forme de manipulation psychologique visant à extirper des informations confidentielles d’une personne ou d’une entreprise. Il existe différents types de mails de phishing :
- Le spearphishing, généralement basé sur l’usurpation d’identité, cible une personne ou un petit groupe de personnes dans le but d’obtenir des informations confidentielles.
- Le whaling est identique au spearphising sauf qu’il vise exclusivement des personnes d’entreprise de haut rang.
- Le phishing par URL a pour objectif que la victime clique sur un lien frauduleux, ce qui pourrait entraîner le téléchargement d’un virus ou mener à une page ou des données confidentielles seraient requises.
IA hybride et Deep Learning au service de la cybersécurité
Depuis quelques années, tout le monde en parle. La solution serait de se doter d’une Intelligence Artificielle, plus précisément d’un algorithme d’apprentissage profond (Deep Learning), pour aider à analyser et donc à détecter les cyberattaques. L’IA est en effet en capacité de s’appuyer sur d’énormes volumes de données pour détecter les mails de phishing et donc agir vite (plus vite que l’être humain ?) quant à cette cyberattaque.
Néanmoins et comme toujours avec le Deep Learning, cela nécessite préalablement la constitution d’une base de données regroupant un grand nombre d’emails labellisés de nature « emails de phishing » mais aussi « emails normaux ». De surcroit, cette base de données doit être équilibrée, c’est-à-dire qu’elle ne doit pas avoir une classe surreprésentée par rapport à une autre, pour éviter que lors de l’apprentissage par les algorithmes de Deep Learning, il y ait un surapprentissage, c’est-à-dire qu’un modèle apprenne trop les particularités de la base de données sur laquelle il s’est entraîné.
Par ailleurs, la détection reste d’autant plus complexe que le corps d’un email, même de phishing, peut être vaste. Il est donc nécessaire de mettre en place des prétraitements pour « nettoyer » le contenu de l’email d’informations à la fois non pertinentes et polluantes pour un apprentissage efficace. Par exemple :
- Passage du corps de l’email en minuscule,
- Réduction de la ponctuation,
- Tokenization
- Lemmatisation,
- Etc…
Aujourd’hui, de plus en plus de solutions apparaissent sur le marché et revendiquent une capacité de détection fiable et automatisée 24h/24, 7jours/7, des cybermenaces.
Le BRMS au service de la détection du Phishing ?
Malgré tout, il y a sans doute une autre voix consistant à mettre en place une IA hybride qui conserve bien entendu un dispositif d’algorithme d’apprentissage, complété par un dispositif d’inférence cognitive.
Spécialiste de la mise en place de solution de moteurs de règles / BRMS (Business Rules Management System), Pacte Novation travaille depuis de nombreuses années sur la complémentarité du Deep Learning avec des techniques de systèmes expert / moteurs de règles. Ce qui s’appelle l’IA Hybride. Pour rappel, les solutions de BRMS permettent la transposition d’une expertise humaine en règles métier qui pour certaines solutions sont des expressions fonctionnelles écrites en langage naturel.
Dans le contexte de la détection d’emails de phishing, un email, quel qu’il soit, est toujours constitué des mêmes parties : l’expéditeur, l’objet, le corps du mail, l’heure, la date et de liens. Si le corps du mail est traité avec une IA de type algorithme d’apprentissage, on peut aisément constituer des règles de contrôles et de filtres sur l’adresse de l’expéditeur, le domaine utilisé, les plages d’horaires durant lesquelles ces emails sont reçus, l’objet de l’email et potentiellement les liens de l’email.
Ainsi, nous pourrions avoir par exemple :
- Une table de décision donnant un score de détection d’un email de phishing en fonction du nombre de chiffres dans l’adresse email :

- Une règle sur le pays d’origine de l’expéditeur :
Si le pays d’origine de l’expéditeur de l’email n’est pas parmi (« fr », « com », « net », « gov », « edu », « org », « info ») alors affecter le score expéditeur à 40.
- Une table de décision donnant un score de détection selon l’heure d’envoi de l’email :
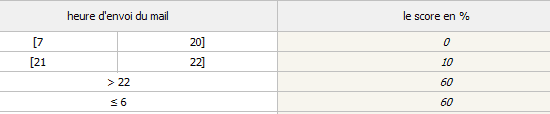
Une IA hybride convaincante et adaptable
Cette approche hybride conserve donc sa capacité de détection fiable et automatisée tout en laissant la possibilité avec une expertise humaine d’adapter simplement et rapidement les règles de contrôle et de filtrage dans la détection d’une cyberattaque via un email de phishing.

Nous sommes intervenus dans le cadre d’atelier/ soutien au métier, Conception et réalisation des services de décisions. Nous avons également dispensé des formations ODM dans la partie Métier.






